The Memory Bottleneck | The Neural Search Shift
We have covered how the AI reads (Transformers), what it counts (Tokens), where it maps ideas (Vector Space), and how it focuses (Attention). Now, we discuss its limitations. The AI is not omniscient; it has a very specific, finite memory span.
We tend to think of AI as a supercomputer with infinite memory. It isn’t. Every LLM has a “Context Window”—a strict limit on how much text it can “hold” in its brain at any single moment. If your content is too bloated, or if it appears too late in the conversation, it literally “falls off the edge” of the AI’s memory. In this episode, we learn how to survive the bottleneck.
Part 1: The Decoder (The Science)
The Sliding Window of Relevance
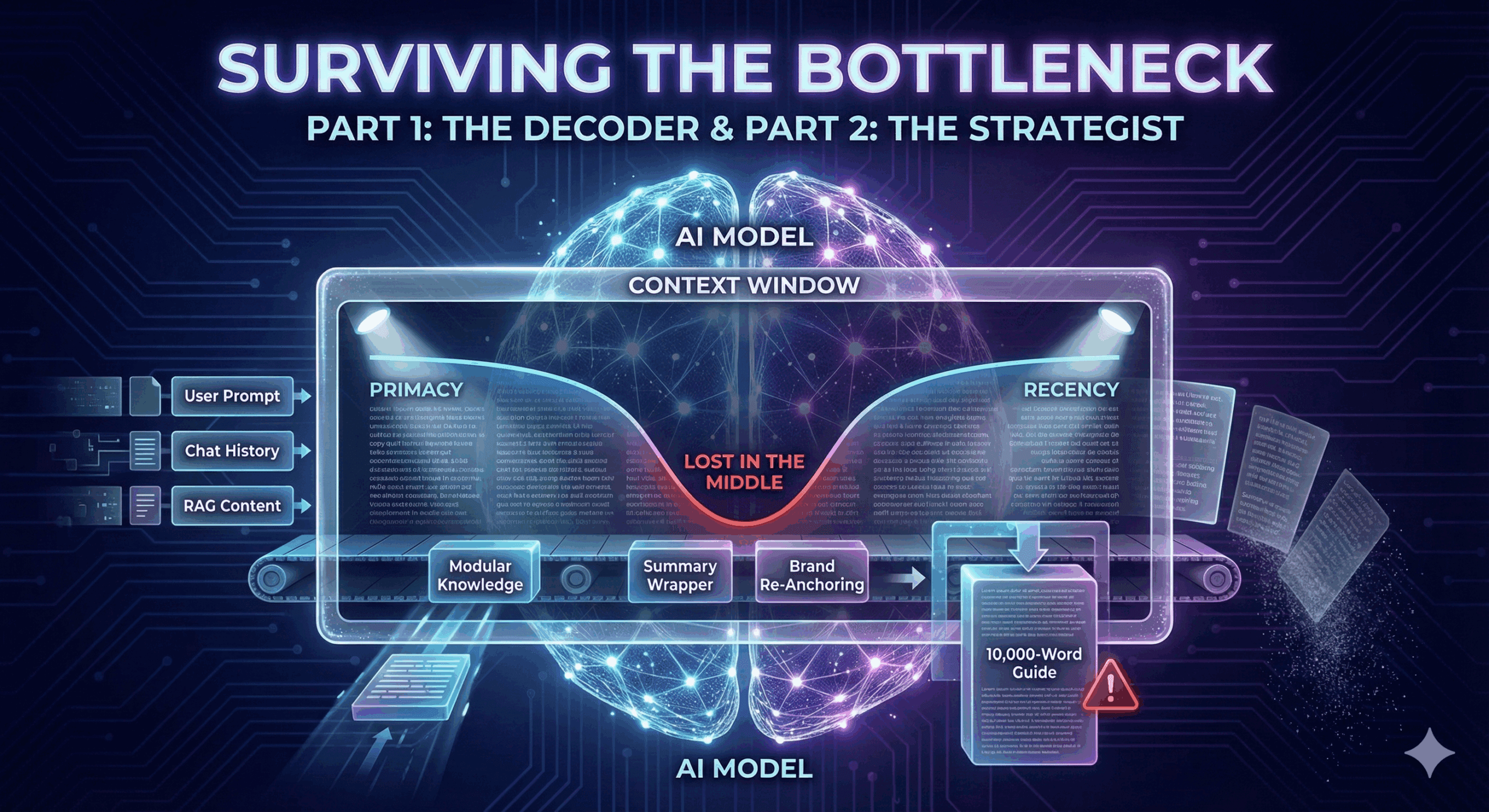
The Context Window is the amount of text (measured in tokens) the model can consider when generating a response. This includes:
- The User’s Instructions (The Prompt).
- The History of the Chat.
- Your Content (Retrieved via RAG).
1. The “First-In, First-Out” Problem Think of the Context Window like a conveyor belt.
- As new information is added (the user asks a follow-up question), the oldest information falls off the back of the belt.
- If your brand was mentioned 20 turns ago in a chat, and the context window fills up, you are gone. The AI has “forgotten” you.
2. The “Lost in the Middle” Phenomenon Stanford researchers discovered a glitch in the matrix: LLMs are great at remembering the beginning of a document (Primacy) and the end (Recency).
- The Glitch: They are terrible at remembering details buried in the middle.
- If you paste a 5,000-word case study into the Context Window, the model’s accuracy on facts located at word #2,500 drops significantly. The “Attention Mechanism” creates a U-shaped curve of performance.
3. RAG and The Squeeze When a search engine uses RAG (Retrieval-Augmented Generation) to answer a question, it fetches multiple sources (maybe your site and 4 competitors).
- It has to jam all of these snippets into one Context Window to generate the answer.
- If your content is bloated, the system might truncate it (cut it off) to make room for a competitor who wrote more concisely.
Part 2: The Strategist (The Playbook)
Optimization for Small Windows
You are competing for real estate in a very cramped room. Your strategy must shift from “Comprehensive Guides” to “Modular Knowledge.”
1. Modular Content Strategy Stop writing “The Ultimate 10,000-Word Guide to Everything.”
- Why: It clogs the Context Window and triggers the “Lost in the Middle” effect.
- The Strategy: Break massive guides into distinct, interlinked H2s or separate pages.
- The Benefit: When the RAG system searches for an answer, it can pull just the relevant module (e.g., “Step 3: Pricing”) without having to ingest the irrelevant history of the industry. This fits perfectly into the window.
2. The “Summary Wrapper” Technique Since LLMs struggle with the middle, you need to reinforce your key entities at the edges.
- The Strategy: End every section or article with a “Key Takeaways” bulleted list.
- Why: This puts your most critical data at the “Recency” position (the end of the text), which is the sweet spot for the Attention Mechanism. It gives the AI a second chance to “memorize” your offer before it generates the answer.
3. Brand “Re-Anchoring” In long-form content, don’t just say “we” or “the platform.”
- The Risk: If the AI splits your content into chunks, a chunk that just says “The platform offers 99% uptime” is weak. Which platform?
- The Strategy: Periodically re-state your Brand Name + Category. “ContentXir’s analytics platform offers 99% uptime.”
- This ensures that no matter which “slice” of your content gets pulled into the Context Window, the brand association remains intact.
ContentXir Intelligence
The “Token ROI” At ContentXir, we think about Token ROI (Return on Ingestion).
- Search engines pay money (compute costs) to process your tokens.
- If they have to process 2,000 tokens of yours to get 1 answer, vs. 500 tokens of a competitor to get the same answer, the competitor has a higher Token ROI.
- Over time, systems optimize for efficiency. Bloated content is expensive content.
Action Item for S01E05: The “Middle-Earth” Audit.
- Take your longest blog post.
- Look at the content in the exact middle (the 50% mark).
- Is there a critical CTA or key differentiator buried there?
- Move it. Put it in the Intro (Primacy) or the Conclusion (Recency). Do not leave your best assets in the dead zone.
Next Up on S01E06: Temperature & Hallucination
Related Insights

How Google I/O 2026 Reshuffled the Search Algorithm—And How ContentXIR Empowers Brands to Dominate the Agentic Web
Google just restructured its search core around Gemini 3.5 Flash, 24/7 background Search Agents, and dynamic Generative UI. Learn how ContentXIR’s causal engine delivers the diagnostic insights needed to survive this new age of SEO.

The Neural Search Shift Season 04: GEO Protocols (The Finale) Episode 07: A/B Testing for Algorithms
We have spent this season re-engineering your content, your code, and your PR for the Generative AI era. But how do you actually know if it is working? In the…

The Neural Search Shift Season 04: GEO Protocols (The New Playbook) Episode 06: The Itinerary Engine
For brick-and-mortar businesses, event spaces, and localized services, the game has fundamentally changed. The “Map Pack” is no longer the final destination. Users are no longer asking search engines to…