Visual Search & Multi-Modal Indexing | see how the AI is watching you
We are moving beyond text. The most profound shift in AI over the last 12 months isn’t just that it got smarter at reading—it’s that it learned to see. If your content strategy relies on heavy text broken up by decorative stock photos, the AI is scoring you poorly.
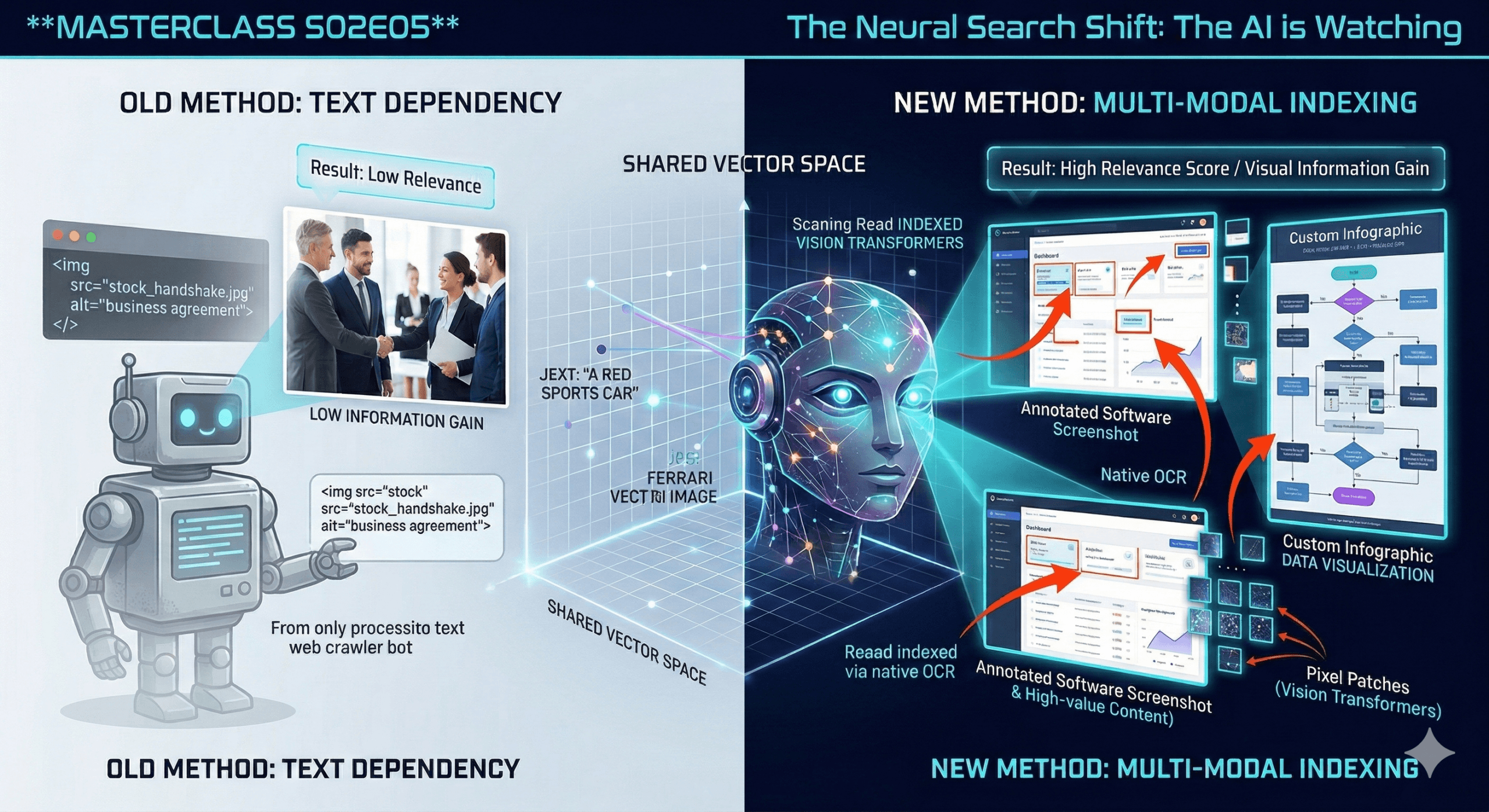
For a decade, search engines were practically blind. They looked at an image on your website and saw an empty black box, relying entirely on your “Alt-Text” string to guess what was inside. Today, search engines are Multi-Modal. They process pixels using advanced Computer Vision. They can read the charts, analyze the screenshots, and recognize the context. In this episode, we decode why generic stock photos are actively harming your Generative Engine Optimization (GEO) and how to design for a bot that can see.
Part 1: The Decoder (The Science)
Vision Transformers and The Shared Map
To understand why the “smiling people pointing at a laptop” stock photo is dead, you have to understand how a Multi-Modal AI processes media.
1. The Old Way: Alt-Text Dependency The traditional crawler was a text-only machine. If you uploaded an image of a complex sales funnel, the bot learned absolutely nothing from the image itself. It only read your <img alt="sales funnel diagram"> tag. The image was just decoration.
2. The New Way: Vision Transformers (ViT) Modern models (like Gemini 1.5, GPT-4o, and Claude 3.5) use Vision Transformers.
- Instead of breaking a sentence into text “Tokens,” they break an image into Pixel Patches.
- The AI analyzes the relationship between these patches, recognizing shapes, text (via native OCR), faces, and data structures. It literally “reads” the image.
3. The Shared Vector Space This is the breakthrough. In a Multi-Modal model, text and images live in the exact same mathematical universe (Vector Space).
- The text string “A red sports car” and a JPG of a Ferrari are converted into numbers and plotted at the exact same coordinates.
- The Reality Check: When a user asks an AI Overview a question, the AI isn’t just retrieving text to answer it. It is retrieving the image vectors too.
Part 2: The Strategist (The Playbook)
Visual Information Gain
If the AI is analyzing your images as deeply as your paragraphs, you must treat your imagery as Data, not decoration.
1. The “Stock Photo” Penalty Stock photos have zero “Information Gain.”
- The Mechanism: When the AI analyzes a stock photo of a handshake, it maps it to a highly generic vector (“Business agreement”). Millions of other websites have this exact same vector.
- The Result: It adds zero unique value to your page’s overall “Relevance Score.” It is empty calories for the algorithm. Stop using them.
2. Data Visualization is Text SEO Because Vision Transformers excel at OCR (Optical Character Recognition), any text embedded inside your image is now indexed and understood.
- The Strategy: Turn your bullet points into custom infographics, flowcharts, or graphs.
- Why it works: When Google AI Overviews or ChatGPT Search generate an answer about a complex process, they strongly prefer to cite and display a clear, step-by-step diagram. A custom graph gives the AI a high-density, easily verifiable “Fact Block” to serve to the user.
3. The “Annotated Evidence” Technique If you are writing a software tutorial or a product review, a raw screenshot is good, but an annotated screenshot is a superpower.
- The Strategy: Add big red arrows, highlight boxes, and text labels directly onto your screenshots.
- Why it works: You are directing the Vision Transformer’s “Attention Mechanism.” By visually isolating the specific button or feature you are talking about, you reduce the mathematical noise in the image, making the AI highly confident that your image answers the user’s specific “How-to” query.
ContentXir Intelligence
Visual Entropy (The New Image Metric) At ContentXir, when we audit a page’s layout, we look at Visual Entropy—a measure of how much unique information the imagery provides.
- A page with 3,000 words of brilliant text but 3 generic stock photos has low visual entropy. The AI sees a missed opportunity.
- A page with 1,500 words of text, accompanied by 2 proprietary data charts and 1 custom framework diagram, has massive visual entropy.
- The Insight: Multi-modal AI engines are explicitly trained to reward pages that explain concepts using multiple formats (Text + Image) simultaneously.
Action Item for S02E05: The “Hero Image” Purge.
- Open the highest-traffic blog post on your site.
- Look at the “Hero Image” at the top of the article. Is it a generic stock photo?
- The Fix: Delete it. Have a designer (or use an AI image generator) create a custom graphic that visually summarizes the core thesis or data point of the article. Make the image work for its crawl budget.
Next Up on S02E06:
- Title: Conversational Queries & Voice 2.0
- Topic: The search bar is turning into a chat window. We explore how “Keywords” are morphing into “Prompts,” and how to optimize for users who ask 40-word questions instead of 4-word fragments.
Related Insights

How Google I/O 2026 Reshuffled the Search Algorithm—And How ContentXIR Empowers Brands to Dominate the Agentic Web
Google just restructured its search core around Gemini 3.5 Flash, 24/7 background Search Agents, and dynamic Generative UI. Learn how ContentXIR’s causal engine delivers the diagnostic insights needed to survive this new age of SEO.

The Neural Search Shift Season 04: GEO Protocols (The Finale) Episode 07: A/B Testing for Algorithms
We have spent this season re-engineering your content, your code, and your PR for the Generative AI era. But how do you actually know if it is working? In the…

The Neural Search Shift Season 04: GEO Protocols (The New Playbook) Episode 06: The Itinerary Engine
For brick-and-mortar businesses, event spaces, and localized services, the game has fundamentally changed. The “Map Pack” is no longer the final destination. Users are no longer asking search engines to…